Benefits of Using IBM Technologies in Insurance

Contents:
- Business Value of Watson Services.
- Gentle Intro to Watson Services.
** Technical Part **
- Description of the project assets.
- Maintenance of models through the jupyter notebook.
- Maintenance of models thorugh the UI.
. . . . . . Business Value from Watson Services . . . . . .
(making your AI more trusted in a proven and automated way)

Each year we are more and more influenced by AI models making decisions that influence our lives.
Are you applying for a new job?
Are you taking a loan?
Are you getting a specific treatment?
In all those situations, it may be the case that AI models infused in institutional processes are making decisions impacting your future.
What can we do to be sure those decisions are right? We can make AI more trusted and more transparent. AI models should meet business KPIs but also they should be fair, just, and not exclude anybody.
You can make such AI models using Watson Machine Learning and Watson OpenScale. These are tools to automate the process of checking on AI models if they working towards your business goals.
Watson services allow you to check your AI solutions for compliance with industry. On top of that they allow you to keep an eye on speficic features of your working AI model:
- Quality
- Drift
- Fairness
- Explainability
The Value of Watson Machine Learning
Watson Machine Learning puts the client’s model on IBM Cloud, making it easily available for use, like a web service.
Watson Machine Learning is managed through Watson Studio, the online environment that enables the creation of end-to-end Analytics of Machine Learning solutions.
The ML model placed on Watson Machine Learning can be versioned, making it quicker to try new versions or go back to the previous version of the model.
When the client’s model is hosted on Watson Machine Learning we can add a whole layer of model analytics using Watson Openscale.

The Value of Watson OpenScale
Watson OpenScale helps organizations maintain regulatory compliance by tracing and explaining AI decisions across workflows, and intelligently detecting and correcting bias to improve outcomes.
OpenScale provides monitors tracking metrics of the model automatically:
- Quality Monitor checks the model’s core quality metrics.
- Drift Monitor checks the model’s accuracy drop and data inconsistency.
- Fairness Monitor keeps an eye on defined minorities against how the same are treated by the model.
- Explainability Monitor delivers information about which data influences the model outcomes the most.

The Value of Cloud Pak for Data
Cloud Pak for Data is the AI & analytics platform for small or big companies. Chatbots, Natural Language Processing, Neural Networks, Machine Learning models - you can build AI that will take your applications to the next level.
An important feature of Cloud Pak for Data is its holistic approach: data preparation, team collaborations, and all activites to build your AI can happen here, all at once. Also, products like AutoAI enable buldiing AI by professionals with little or no knowledge of Data Science.
The greatest thing about Cloud Pak for Data, is that you can deploy and leverage it on any cloud, or any server able to host Red Hat OpenShift.
. . . . . . Gentle Intro to Watson Services . . . . . .
(deploying AI models as API, monitoring AI models in production)
Watson Machine Learning (WML)
Watson Machine Learning is an IBM Cloud service that supports popular frameworks such as Scikit-learn, TensorFlow, PyTorch, and Keras to build and deploy models. With Watson ML you can store, version and deploy models via online deployment. With those abilities Watson ML can helps you build reliable MLOps environment in the area of model versioning and model maintenance.
In Watson ML you can create:
- Spaces (similar to projects)
- Deployments (deployed models)
Many deployments can live on one space.
Deployments can be:
- batch (working in the background)
- online (always ready to take API calls)
To read more go here.
Watson OpenScale (WOS)
Watson OpenScale is a service on IBM Cloud that helps you monitor your existing models on bias, drift, fairness, and explainability.
In OpenScale you can create:
- Subscription (kind of connection to model sitting on Watson ML)
- Monitors attached to subscription (making checks on your models)
One Subscription hosts many Monitors. To read more go here.
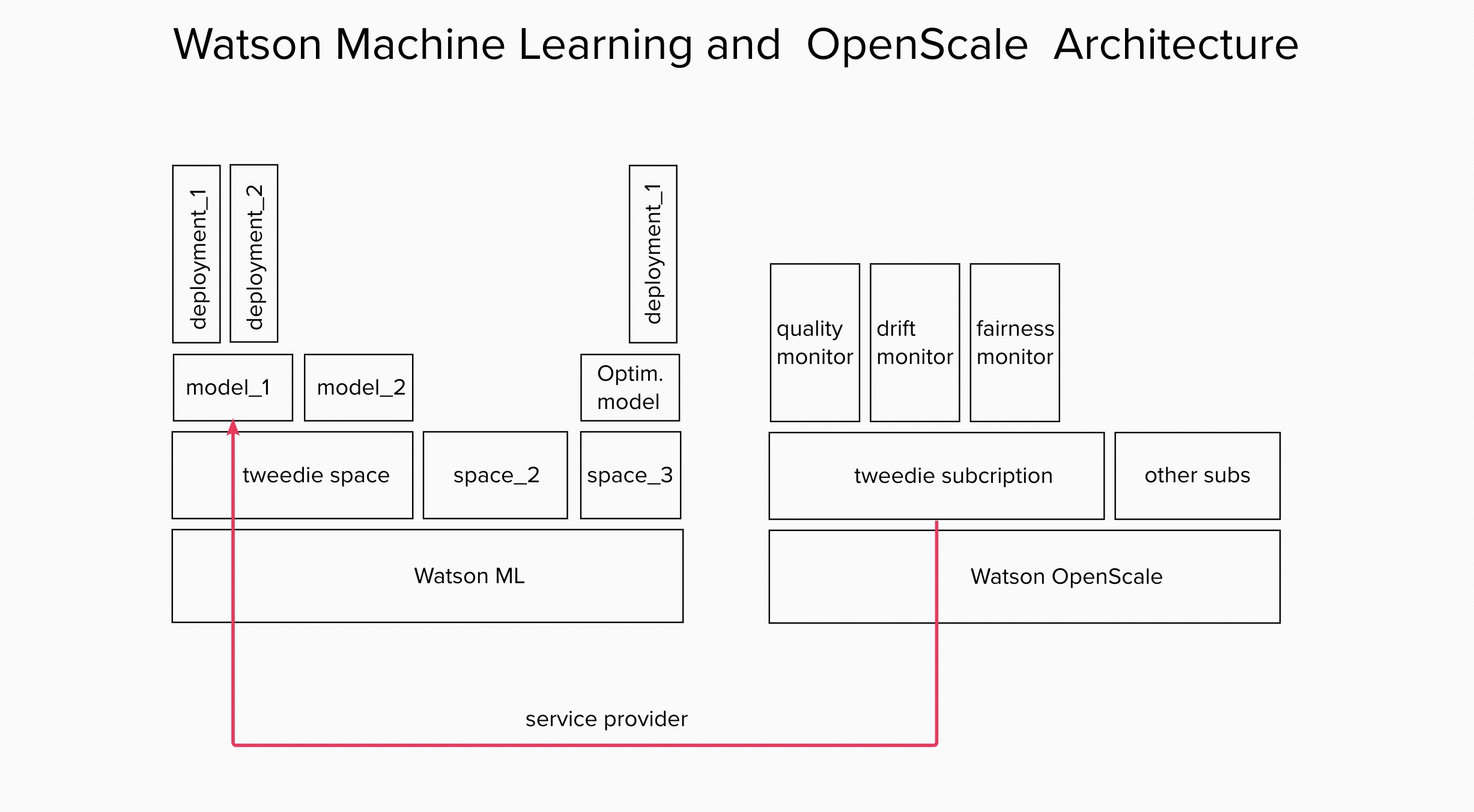
Overall architecture view of Watson Machine Learning and Watson OpenScale working together.
. . . . . . Description of the project assets . . . . . .
IBM & Ablera: integrative architecture
- Platform: Watson Studio on Cloud Pak For Data serves as layer to store and connect code, service instances, and retrieve output using APIs.
- Environment: Python 3.9 on Jupyter Notebook
- Data preprocessing and modelling: used on General Linear Models specific to the insurance industry.
- Model deployment: we used Watson Machine Learning to store, deploy and score the model.
- Model performance: we used Watson OpenScale to create monitors that assess the model and data drift, quality and fairness.
- Application: Ablera infused AI into the existing application, integrating outcomes from Watson Machine Learning and OpenScale.
IBM Specifics
- Cloud Object Storage
- Watson Studio (project) on Cloud Pak for Data as-a-Service (CP4DaaS): can automate preprocessing pipelines from csv or db.
- Watson Machine Learning: stores multiple models into a single space. Models can be redeployed in a end-to-end lifecycle.
- Watson OpenScale: AI capabilities to assess the model, generate corrected predictions and suggest model retraining.
. . . . . . Maintenance of models through Jupyter Notebook . . . . . .
The notebook for Ablera - what it does?
The notebook, passed from IBM Client Engineering team to the Ablera team, creates the instance of Tweedie Regression on Watson Machine Learning, connecting it with Watson OpenScale monitors for quality, data drift, fairness and explainability.
Basic setup for the notebook
To run the notebook on your environment you need to define following entities:
IBM Cloud setup
- API key to your IBM Cloud environment (the
api_keyvariable in the notebook). To create api key read this. - IBM Cloud Object Storage variables to connect with your IBM COS bucket (following variables in the notebook:
cos_credentials,cos_bucket). To create bucket in IBM COS read this.
Watson Machine Learning setup
- Location and deployment space ID (
locationandspace_idvariable in Watson ML part of the notebook). Deployment spaces are created in Watson Studio, to read more about it go here. - Model name, deployment name and version (
MODEL_NAME,DEPLOYMENT_NAME, andVERSIONvariables in the notebook). Those variable define: - the name of the model pushed on Watson ML instance - the deployment name (or the model that is published to use) - versioning of two above - versioning of the software specification that is ready for use with the model (VERSION var is added to variabletweedie_sw_spec)
Watson OpenScale setup
- location and data mart instance ID (
locationvariable andinstancevariable withinservice_credentialsvariable in the notebook) - Name of service provider for OpenScale monitors (
SERVICE_PROVIDER_NAMEvariable) - type of monitors(production, preproduction, test) (
environment_typevariable in the notebook)
Quick re-run of the notebook
For quick re-run you can optionally re-define only following variables:
space_idvariable defining from on which deployment space your model and model deployment will be hosted.SERVICE_PROVIDER_NAME,SERVICE_PROVIDER_DESCRIPTIONandenvironment_typeto define a space for newly created monitors.
API libraries for Watson Machine Learning and Watson OpenScale
To control Watson Machine Learning environment with Python code use ibm-watson-machine-learning library (ibm_watson_machine_learning).
The library itself can be found here.
The documentation for ibm-watson-machine-learning is here.
To control Watson OpenScale environment with Python code use Watson Openscale Python SDK library.
There are two OpenScale libraries:
- older library named
ibm-ai-openscale- (ibm_ai_openscale) it works, but may be deprecated in near future. - recent library named
ibm-watson-openscale(ibm_watson_openscale) - let’s use this one.
The library for ibm-watson-openscale is here.
The documentation for ibm-watson-openscale is here.
Commands useful in maintenance of Watson Services environment:
- Watson Machine Learning (WML) -
wml_client.software_specifications.list(100) - lists software specs for given space.
wml_client.repository.list() - lists models living in given space.
wml_client.repository.delete('_guid number of repository_')- deletes specific model ATTENTION: you need to delete model deployments before you delete model. Use two commnads below to list and delete model deployments.
wml_client.deployments.list() - lists deployed models on given space.
wml_client.deployments.delete('1ac8bbb1-328c-41be-84e0-5953ae667d02') - deletes specific deployed model.
- Watson OpenScale -
wos_client.data_marts.show() - lists datamarts connected to our OpenScale instance.
wos_client.service_providers.show(limit=None) - lists data providers in OpenScale instance.
wos_client.subscriptions.show(limit=None) - lists subscriptions in OpenScale instance.
wos_client.data_sets.list - lists data sets kept by OpenScale (like payload logging, feedback data, errors).
wos_client.data_sets.show_records(data_set_id='_here is id_') - shows one data set.
wos_client.monitor_instances.show() - lists all created monitors.
wos_client.monitor_instances.delete('monitor_id') - deletes specific monitor (it’s often not enough and you need to delte whole subsription).
How do you delete old service providers in OpenScale:
-
See all providers:
wos_client.service_providers.show(limit=None) -
Copy the id of chosen provider from output of above command.
-
Delete selected provider:
wos_client.service_providers.delete(copied_id) -
Check if provider is gone:
wos_client.service_providers.show(limit=None)
How do you delete old data sets in OpenScale:
(OpenScale records various files, called data sets, needed for monitors’ work. Sometimes we need to remove old, unused data sets manually.)
-
List datasets:
wos_client.data_sets.list() -
Copy the id of chosen data set from output of above command.
-
Delete selected data set:
wos_client.data_sets.delete(copied_id) -
Check if data set is gone:
wos_client.data_sets.list()
. . . . . . Maintenance of models through the UI . . . . . .
Work in progress . . .
materials to add:
read about configuring drift monitor
read about how to interpret drift monitor results

